GitHub API Commit Flow
This blog has no storage. That is because I host it at heroku and no matter how easy heroku might be, they have no simple solution for storage.
I mean hard drive storage, database storage is not an issue. I want to be able to upload my screenshots for articles without hassle nor without pushing them into a postgres database.
Instead I am using GitHub to host my image content, for example:

Feel free to take and extend at will, the license is simply don’t do evil.
How does it work?
Basically I use GitHub as a CDN by using GitHub pages to let GitHub host my repository under my domain: cdn.openmindmap.org. All files in the that repo are then reachable via https://cdn.openmindmap.org/content/XXXX.
The next problem was then to update that content. Locally I created a flow that would upload content and store it locally. That does not work with heroku. I needed to create a commit and upload my content to GitHub.
I already have the upload interface - for obvious reasons the upload button isn’t active. It allows me to copy markdown snippets into my documents and upload content. The Node-RED flow for CDN management is continously being improved but available.
What I needed was a way to do a GitHub commit via API without having local storage or copy of the repo. Stackoverflow engineering to the rescue. A quick look on npmjs.org and @octokit/rest seemed to be the package I needed.
Although after unsuccessfully trying to get it to work with the new GitHub fine grained token (which are beta), I reverted to using “raw” API requests with the “classic” GitHub developer token, so the package is basically overkill.
GitHub Functionality flow
All functionality required for doing a commit to a GitHub repo without a local copy is encapsulated in the following flow:
[
{
"id": "9ad713be26ac2025",
"type": "function",
"z": "390ee0021ded4910",
"name": "get tree for sha",
"func": "try {\n var octokit = new octokitRest.Octokit({ \n auth: process.env.GITHUB_TOKEN \n });\n} catch(e) {\n node.error(\"init octokit\", {\n ...msg,\n error: e\n })\n return undefined;\n}\n\n/**\n * Msg attributes:\n * - owner: github repo owner\n * - repo: github repo name\n * - payload: sha of tree (i.e. directory)\n * \n * Return:\n * - payload: tree of the sha, this will be an array with one entry per member of tree\n */\n\ntry {\n \n octokit.request(\"GET /repos/{owner}/{repo}/git/trees/{tree_sha}\", {\n owner: msg.owner,\n repo: msg.repo,\n tree_sha: msg.payload\n }).then( (resp) => {\n node.send({ ...msg, payload: resp.data.tree})\n }).catch(function (e) {\n node.error(\"obtaining tree\", { ...msg, error: e })\n });\n\n} catch (e) {\n node.error(\"something went wrong\", { ...msg, error: e})\n}\n",
"outputs": 1,
"noerr": 0,
"initialize": "",
"finalize": "",
"libs": [
{
"var": "octokitRest",
"module": "@octokit/rest"
},
{
"var": "process",
"module": "process"
}
],
"x": 702,
"y": 493.79999999999995,
"wires": [
[
"30c0f36427ec6c9d"
]
]
},
{
"id": "774f89a0fcfe6965",
"type": "comment",
"z": "390ee0021ded4910",
"name": "Requires @octokit/rest npm package and process.env.GITHUB_TOKEN",
"info": "A series of GitHub functions for handling a github repo via API. The intention is to commit content to a github repo without have a local copy of it. \n\nThis is designed to work on a server without any storage.\n\nTaken from this stackoverflow answer:\n\nhttps://stackoverflow.com/questions/11801983/how-to-create-a-commit-and-push-into-repo-with-github-api-v3\n\nGitHub API documentation: https://docs.github.com/en/rest/git/trees?apiVersion=2022-11-28\n\n---\n\nEnvironment variable GITHUB_TOKEN:\n\nThe github token is a classic personal token, the new fine-grain token doesn't work with @octokit.\n\nAll the permissions needed on the token is \"repo\" (with all sub-options).\n\nFound here: https://github.com/settings/tokens --> classic token!!!\n\n---\n\nUpdate package.json to include \"@octokit/rest\": \"latest\" **HOWEVER** this will require NodeJS >=18 which the docker image of the Node-RED 3.0.2 **DOES NOT HAVE**, it still uses NodeJS 16 --> this means: don't try this with the current 3.0.2 docker image, it will only fail.",
"x": 752,
"y": 95,
"wires": []
},
{
"id": "f8774c1c32f1631d",
"type": "function",
"z": "390ee0021ded4910",
"name": "current repo revision (sha)",
"func": "try {\n var octokit = new octokitRest.Octokit({ \n auth: process.env.GITHUB_TOKEN \n });\n} catch(e) {\n node.error(\"init octokit\", {\n ...msg,\n error: e\n })\n return undefined;\n}\n\n/**\n * Msg attributes:\n * - owner: github repo owner\n * - repo: github repo name\n * - branch: branch name\n * \n * Return:\n * - payload: current revision of repo\n */\n\ntry {\n\n octokit.request(\"GET /repos/:owner/:repo/branches/:branch\", {\n owner: msg.owner,\n repo: msg.repo,\n branch: msg.branch,\n }).then( (resp) => {\n node.send({ ...msg, payload: resp.data.commit.sha})\n }).catch(function (e) {\n node.error(\"obtaining latest sha\", { ...msg, error: e })\n });\n\n} catch (e) {\n node.error(\"request failure\", { ...msg, error: e})\n}\n",
"outputs": 1,
"noerr": 0,
"initialize": "",
"finalize": "",
"libs": [
{
"var": "octokitRest",
"module": "@octokit/rest"
},
{
"var": "process",
"module": "process"
}
],
"x": 732,
"y": 385,
"wires": [
[
"30c0f36427ec6c9d"
]
]
},
{
"id": "c90bd91e45e1ac7e",
"type": "link in",
"z": "390ee0021ded4910",
"name": "[github] current repo version",
"links": [],
"x": 480,
"y": 213.99996337890627,
"wires": [
[
"f8774c1c32f1631d"
]
]
},
{
"id": "30c0f36427ec6c9d",
"type": "link out",
"z": "390ee0021ded4910",
"name": "link out 91",
"mode": "return",
"links": [],
"x": 1107,
"y": 822.9999694824219,
"wires": []
},
{
"id": "43d3a872c31bb664",
"type": "link in",
"z": "390ee0021ded4910",
"name": "[github] get tree for sha",
"links": [],
"x": 480,
"y": 391.1999633789063,
"wires": [
[
"9ad713be26ac2025"
]
]
},
{
"id": "ef98698a4b696e66",
"type": "function",
"z": "390ee0021ded4910",
"name": "create blob",
"func": "try {\n var octokit = new octokitRest.Octokit({ \n auth: process.env.GITHUB_TOKEN \n });\n} catch(e) {\n node.error(\"init octokit\", {\n ...msg,\n error: e\n })\n return undefined;\n}\n/**\n * Msg attributes:\n * - owner: github repo owner\n * - repo: github repo name\n * - payload: base64 encoded content for blob\n * \n * Return:\n * - payload: sha of newly created blob\n */\n\ntry {\n\n octokit.request(\"POST /repos/:owner/:repo/git/blobs\", {\n owner: msg.owner,\n repo: msg.repo,\n content: msg.payload,\n encoding: \"base64\"\n }).then( (resp) => {\n node.send({ ...msg, payload: resp.data.sha})\n }).catch(function (e) {\n node.error(\"creating blob\", { ...msg, error: e })\n });\n\n} catch (e) {\n node.error(\"something went wrong\", { ...msg, error: e})\n}\n",
"outputs": 1,
"noerr": 0,
"initialize": "",
"finalize": "",
"libs": [
{
"var": "octokitRest",
"module": "@octokit/rest"
},
{
"var": "process",
"module": "process"
}
],
"x": 692,
"y": 602.5999999999999,
"wires": [
[
"30c0f36427ec6c9d"
]
]
},
{
"id": "5226230f86c9c784",
"type": "function",
"z": "390ee0021ded4910",
"name": "create tree for blobs",
"func": "try {\n var octokit = new octokitRest.Octokit({ \n auth: process.env.GITHUB_TOKEN \n });\n} catch(e) {\n node.error(\"init octokit\", {\n ...msg,\n error: e\n })\n return undefined;\n}\n\n/**\n * Msg attributes:\n * - owner: github repo owner\n * - repo: github repo name\n * - payload: array of blobs, each blob is an object with:\n * - path: filename of the blob in the repo, with path, i.e., dir1/dir2/filename.txt\n * - sha: the sha of the blob created initially using the create blob function\n * - parent_sha: the current sha of the repo, the return value of current repo revision\n * \n * Return:\n * - payload: sha of newly created tree\n */\n\ntry {\n var tree = msg.payload.map(function(blb){\n return {\n ...blb,\n mode: \"100644\",\n type: \"blob\"\n }\n });\n\n octokit.request(\"POST /repos/:owner/:repo/git/trees\", {\n owner: msg.owner,\n repo: msg.repo,\n base_tree: msg.parent_sha,\n tree: tree\n }).then((resp) => {\n node.send({ ...msg, payload: resp.data.sha })\n }).catch(function (e) {\n node.error(\"creating commit\", { ...msg, error: e })\n });\n \n} catch (e) {\n node.error(\"something went wrong\", { ...msg, error: e})\n}\n",
"outputs": 1,
"noerr": 0,
"initialize": "",
"finalize": "",
"libs": [
{
"var": "octokitRest",
"module": "@octokit/rest"
},
{
"var": "process",
"module": "process"
}
],
"x": 722,
"y": 711.3999999999999,
"wires": [
[
"30c0f36427ec6c9d"
]
]
},
{
"id": "e68b9f9bac76350a",
"type": "function",
"z": "390ee0021ded4910",
"name": "create commit",
"func": "try {\n var octokit = new octokitRest.Octokit({\n auth: process.env.GITHUB_TOKEN\n });\n} catch (e) {\n node.error(\"init octokit\", {\n ...msg,\n error: e\n })\n return undefined;\n}\n\n/**\n * Msg attributes:\n * - owner: github repo owner\n * - repo: github repo name\n * - payload: the sha of the tree to commit\n * - parent_sha: the current sha of the repo, the return value of current repo revision\n * - author: an object with the following:\n * - name: name of the author of the commit\n * - email: email of the author of the commit\n * - message: commit message\n * \n * Return:\n * - payload: sha of newly commit\n */\n\ntry {\n \n octokit.request(\"POST /repos/:owner/:repo/git/commits\", {\n owner: msg.owner,\n repo: msg.repo, \n message: msg.message,\n author: {\n name: msg.author.name,\n email: msg.author.email\n },\n parents: [\n msg.parent_sha\n ],\n tree: msg.payload\n }).then((resp) => {\n node.send({ ...msg, payload: resp.data.sha })\n }).catch(function (e) {\n node.error(\"creating commit\", { ...msg, error: e })\n });\n\n} catch (e) {\n node.error(\"something went wrong\", { ...msg, error: e })\n}\n",
"outputs": 1,
"noerr": 0,
"initialize": "",
"finalize": "",
"libs": [
{
"var": "octokitRest",
"module": "@octokit/rest"
},
{
"var": "process",
"module": "process"
}
],
"x": 702,
"y": 820.1999999999998,
"wires": [
[
"30c0f36427ec6c9d"
]
]
},
{
"id": "df3c4b14324197c4",
"type": "function",
"z": "390ee0021ded4910",
"name": "updating head on repo at branch - aka committing commit",
"func": "try {\n var octokit = new octokitRest.Octokit({\n auth: process.env.GITHUB_TOKEN\n });\n} catch (e) {\n node.error(\"init octokit\", {\n ...msg,\n error: e\n })\n return undefined;\n}\n\n/**\n * Msg attributes:\n * - owner: github repo owner\n * - repo: github repo name\n * - branch: github repo branch to update with the new commit sha\n * - payload: the sha of the commit created\n * \n * Return:\n * - payload: new sha of the branch\n */\n\ntry {\n\n octokit.request(\"PATCH /repos/:owner/:repo/git/refs/heads/:branch\", {\n owner: msg.owner,\n repo: msg.repo,\n branch: msg.branch,\n sha: msg.payload\n }).then(function (resp) {\n node.send({ ...msg, resp: resp.data.sha })\n }).catch(function (e) {\n node.error(\"committing commit\", { ...msg, error: e })\n });\n\n} catch (e) {\n node.error(\"something went wrong\", { ...msg, error: e })\n}\n",
"outputs": 1,
"noerr": 0,
"initialize": "",
"finalize": "",
"libs": [
{
"var": "octokitRest",
"module": "@octokit/rest"
},
{
"var": "process",
"module": "process"
}
],
"x": 842,
"y": 929,
"wires": [
[
"30c0f36427ec6c9d"
]
]
},
{
"id": "08d2d7135f31a878",
"type": "link in",
"z": "390ee0021ded4910",
"name": "[github] create blobs",
"links": [],
"x": 480,
"y": 568.3999633789062,
"wires": [
[
"ef98698a4b696e66"
]
]
},
{
"id": "78d886e3f8af26b7",
"type": "link in",
"z": "390ee0021ded4910",
"name": "[github] create tree from blobs",
"links": [],
"x": 480,
"y": 745.5999633789062,
"wires": [
[
"5226230f86c9c784"
]
]
},
{
"id": "ab95f13fbc3a2d5b",
"type": "link in",
"z": "390ee0021ded4910",
"name": "[github] create commit",
"links": [],
"x": 480,
"y": 922.7999633789062,
"wires": [
[
"e68b9f9bac76350a"
]
]
},
{
"id": "2df1a9a310e8a9fd",
"type": "link in",
"z": "390ee0021ded4910",
"name": "[github] update branch head",
"links": [],
"x": 480,
"y": 1099.9999633789062,
"wires": [
[
"df3c4b14324197c4"
]
]
},
{
"id": "85ebf74b798c33b1",
"type": "catch",
"z": "390ee0021ded4910",
"name": "",
"scope": null,
"uncaught": false,
"x": 588,
"y": 1223,
"wires": [
[
"7dc3d4996581f31f"
]
]
},
{
"id": "7dc3d4996581f31f",
"type": "debug",
"z": "390ee0021ded4910",
"name": "github exception",
"active": true,
"tosidebar": true,
"console": false,
"tostatus": false,
"complete": "true",
"targetType": "full",
"statusVal": "",
"statusType": "auto",
"x": 877,
"y": 1223,
"wires": []
}
]
It basically breaks each of the steps in the Stackoverflow answer into a single function node.
To use that flow, I created a bunch of link-call nodes to reference the function nodes.
The upload flow is this:
[
{
"id": "0ff5ee7e1c498515",
"type": "function",
"z": "543929cb2e9c4087",
"name": "set filename",
"func": "msg.filename = (new Date()).getTime() + \"_\" + msg.file.name.replace(/[\\t\\n ]/g, \"_\");\n\nreturn msg;",
"outputs": 1,
"noerr": 0,
"initialize": "",
"finalize": "",
"libs": [],
"x": 279.6667289733887,
"y": 1240.6666679382324,
"wires": [
[
"4a56684319313271"
]
]
},
{
"id": "4027586694c61f7c",
"type": "ui_upload",
"z": "543929cb2e9c4087",
"group": "311ea16f0a12989c",
"title": "upload",
"name": "",
"order": 1,
"width": 12,
"height": 5,
"chunk": "23",
"transfer": "binary",
"x": 259.6667289733887,
"y": 1140.6666679382324,
"wires": [
[
"1452cc35100518f7"
]
]
},
{
"id": "1452cc35100518f7",
"type": "join",
"z": "543929cb2e9c4087",
"name": "",
"mode": "custom",
"build": "buffer",
"property": "payload",
"propertyType": "msg",
"key": "topic",
"joiner": "",
"joinerType": "bin",
"accumulate": false,
"timeout": "",
"count": "",
"reduceRight": false,
"reduceExp": "",
"reduceInit": "",
"reduceInitType": "",
"reduceFixup": "",
"x": 259.6667289733887,
"y": 1189.6666679382324,
"wires": [
[
"0ff5ee7e1c498515"
]
]
},
{
"id": "4a56684319313271",
"type": "base64",
"z": "543929cb2e9c4087",
"name": "",
"action": "",
"property": "payload",
"x": 282,
"y": 1301,
"wires": [
[
"5d478c571be4c6bb"
]
]
},
{
"id": "82cfcfbebabd577b",
"type": "debug",
"z": "543929cb2e9c4087",
"name": "debug 27",
"active": true,
"tosidebar": true,
"console": false,
"tostatus": false,
"complete": "true",
"targetType": "full",
"statusVal": "",
"statusType": "auto",
"x": 1561,
"y": 1474,
"wires": []
},
{
"id": "71532dbe200b659a",
"type": "group",
"z": "543929cb2e9c4087",
"name": "upload content to github as a commit",
"style": {
"label": true
},
"nodes": [
"7a2918984a4bd1b8",
"d9d5c0ebdc62ac6a",
"a7dd8196cabe3baf",
"4b38b527d730f2a8",
"021382567696e288",
"9f06c39b07528554",
"5ea8f134cf490bbc",
"b4f37f1257b91e23",
"5d478c571be4c6bb"
],
"x": 554,
"y": 1011,
"w": 1423,
"h": 333
},
{
"id": "7a2918984a4bd1b8",
"type": "catch",
"z": "543929cb2e9c4087",
"g": "71532dbe200b659a",
"name": "",
"scope": [
"5d478c571be4c6bb",
"4b38b527d730f2a8",
"d9d5c0ebdc62ac6a",
"a7dd8196cabe3baf",
"021382567696e288",
"9f06c39b07528554",
"5ea8f134cf490bbc",
"b4f37f1257b91e23"
],
"uncaught": false,
"x": 1298,
"y": 1303,
"wires": [
[
"82cfcfbebabd577b"
]
]
},
{
"id": "d9d5c0ebdc62ac6a",
"type": "change",
"z": "543929cb2e9c4087",
"g": "71532dbe200b659a",
"name": "blobs",
"rules": [
{
"t": "set",
"p": "blobs",
"pt": "msg",
"to": "[]",
"tot": "json"
},
{
"t": "set",
"p": "blobs[0]",
"pt": "msg",
"to": "{\t \"path\": \"content/\" & msg.filename,\t \"sha\": msg.payload }",
"tot": "jsonata"
}
],
"action": "",
"property": "",
"from": "",
"to": "",
"reg": false,
"x": 977,
"y": 1188,
"wires": [
[
"a7dd8196cabe3baf"
]
]
},
{
"id": "a7dd8196cabe3baf",
"type": "link call",
"z": "543929cb2e9c4087",
"g": "71532dbe200b659a",
"name": "[github] current repo version",
"links": [
"c90bd91e45e1ac7e"
],
"linkType": "static",
"timeout": "30",
"x": 1128,
"y": 1128,
"wires": [
[
"021382567696e288"
]
]
},
{
"id": "4b38b527d730f2a8",
"type": "link call",
"z": "543929cb2e9c4087",
"g": "71532dbe200b659a",
"name": "[github] create blobs",
"links": [
"08d2d7135f31a878"
],
"linkType": "static",
"timeout": "30",
"x": 863,
"y": 1244,
"wires": [
[
"d9d5c0ebdc62ac6a"
]
]
},
{
"id": "021382567696e288",
"type": "change",
"z": "543929cb2e9c4087",
"g": "71532dbe200b659a",
"name": "parent_sha, blobs --> payload, message and author",
"rules": [
{
"t": "set",
"p": "parent_sha",
"pt": "msg",
"to": "payload",
"tot": "msg"
},
{
"t": "set",
"p": "payload",
"pt": "msg",
"to": "blobs",
"tot": "msg",
"dc": true
},
{
"t": "set",
"p": "message",
"pt": "msg",
"to": "file upload from blog.openmindmap.org",
"tot": "str"
},
{
"t": "set",
"p": "author",
"pt": "msg",
"to": "{ \"name\": \"Gerrit Riessen\", \"email\": \"gerrit@openmindmap.org\" }",
"tot": "json"
}
],
"action": "",
"property": "",
"from": "",
"to": "",
"reg": false,
"x": 1291,
"y": 1052,
"wires": [
[
"9f06c39b07528554"
]
]
},
{
"id": "9f06c39b07528554",
"type": "link call",
"z": "543929cb2e9c4087",
"g": "71532dbe200b659a",
"name": "[github] create tree from blobs",
"links": [
"78d886e3f8af26b7"
],
"linkType": "static",
"timeout": "30",
"x": 1529,
"y": 1107,
"wires": [
[
"5ea8f134cf490bbc"
]
]
},
{
"id": "5ea8f134cf490bbc",
"type": "link call",
"z": "543929cb2e9c4087",
"g": "71532dbe200b659a",
"name": "[github] create commit",
"links": [
"ab95f13fbc3a2d5b"
],
"linkType": "static",
"timeout": "30",
"x": 1691,
"y": 1199,
"wires": [
[
"b4f37f1257b91e23"
]
]
},
{
"id": "b4f37f1257b91e23",
"type": "link call",
"z": "543929cb2e9c4087",
"g": "71532dbe200b659a",
"name": "[github] update branch head",
"links": [
"2df1a9a310e8a9fd"
],
"linkType": "static",
"timeout": "30",
"x": 1831,
"y": 1261,
"wires": [
[
"b8c9e6c7fcc40834"
]
]
},
{
"id": "5d478c571be4c6bb",
"type": "change",
"z": "543929cb2e9c4087",
"g": "71532dbe200b659a",
"name": "owner, repo, branch",
"rules": [
{
"t": "set",
"p": "owner",
"pt": "msg",
"to": "gorenje",
"tot": "str"
},
{
"t": "set",
"p": "repo",
"pt": "msg",
"to": "cdn.openmindmap.org",
"tot": "str"
},
{
"t": "set",
"p": "branch",
"pt": "msg",
"to": "main",
"tot": "str"
}
],
"action": "",
"property": "",
"from": "",
"to": "",
"reg": false,
"x": 680,
"y": 1303,
"wires": [
[
"4b38b527d730f2a8"
]
]
},
{
"id": "311ea16f0a12989c",
"type": "ui_group",
"name": "Upload",
"tab": "89a28692fcc0415f",
"order": 1,
"disp": true,
"width": "12",
"collapse": false,
"className": ""
},
{
"id": "89a28692fcc0415f",
"type": "ui_tab",
"name": "Upload",
"icon": "dashboard",
"order": 11,
"disabled": false,
"hidden": false
}
]
Everything is there how this works: file data is uploaded to the server, its converted to base64, pushed to GitHub and then committed.
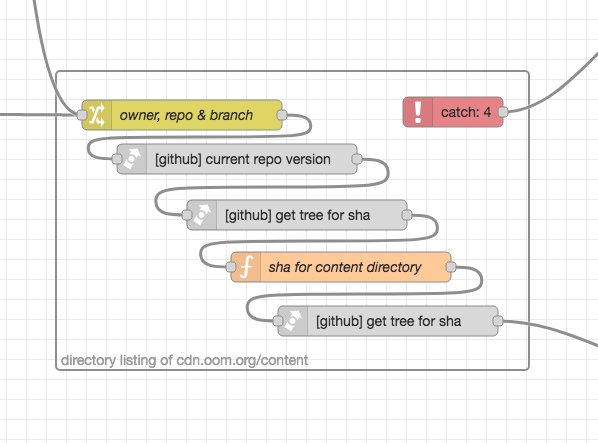
To obtain a list of all available image files, there is an another flow:
[
{
"id": "a60cbee137a9ee18",
"type": "group",
"z": "543929cb2e9c4087",
"name": "directory listing of cdn.oom.org/content",
"style": {
"label": true,
"label-position": "sw"
},
"nodes": [
"f2af85e0334b1b64",
"16594dda64d03fbc",
"778e2f3419f60823",
"6e1784096d436378",
"f5c9ea1631d0aee3",
"b8c9e6c7fcc40834"
],
"x": 2050,
"y": 1692,
"w": 473,
"h": 299
},
{
"id": "f2af85e0334b1b64",
"type": "link call",
"z": "543929cb2e9c4087",
"g": "a60cbee137a9ee18",
"name": "[github] current repo version",
"links": [
"c90bd91e45e1ac7e"
],
"linkType": "static",
"timeout": "30",
"x": 2231,
"y": 1780,
"wires": [
[
"16594dda64d03fbc"
]
]
},
{
"id": "16594dda64d03fbc",
"type": "link call",
"z": "543929cb2e9c4087",
"g": "a60cbee137a9ee18",
"name": "[github] get tree for sha",
"links": [
"43d3a872c31bb664"
],
"linkType": "static",
"timeout": "30",
"x": 2291,
"y": 1836,
"wires": [
[
"778e2f3419f60823"
]
]
},
{
"id": "778e2f3419f60823",
"type": "function",
"z": "543929cb2e9c4087",
"g": "a60cbee137a9ee18",
"name": "sha for content directory",
"func": "\nmsg.payload = msg.payload.filter(function (e) { return e.path == \"content\" })[0].sha;\n\nreturn msg;",
"outputs": 1,
"noerr": 0,
"initialize": "",
"finalize": "",
"libs": [],
"x": 2335,
"y": 1888,
"wires": [
[
"6e1784096d436378"
]
]
},
{
"id": "6e1784096d436378",
"type": "link call",
"z": "543929cb2e9c4087",
"g": "a60cbee137a9ee18",
"name": "[github] get tree for sha",
"links": [
"43d3a872c31bb664"
],
"linkType": "static",
"timeout": "30",
"x": 2382,
"y": 1942,
"wires": [
[
"cc4ae514537b3251"
]
]
},
{
"id": "f5c9ea1631d0aee3",
"type": "catch",
"z": "543929cb2e9c4087",
"g": "a60cbee137a9ee18",
"name": "",
"scope": [
"f2af85e0334b1b64",
"16594dda64d03fbc",
"778e2f3419f60823",
"6e1784096d436378"
],
"uncaught": false,
"x": 2447,
"y": 1733,
"wires": [
[
"a4384dfd3351be34"
]
]
},
{
"id": "b8c9e6c7fcc40834",
"type": "change",
"z": "543929cb2e9c4087",
"g": "a60cbee137a9ee18",
"name": "owner, repo and branch",
"rules": [
{
"t": "set",
"p": "owner",
"pt": "msg",
"to": "gorenje",
"tot": "str"
},
{
"t": "set",
"p": "repo",
"pt": "msg",
"to": "cdn.openmindmap.org",
"tot": "str"
},
{
"t": "set",
"p": "branch",
"pt": "msg",
"to": "main",
"tot": "str"
}
],
"action": "",
"property": "",
"from": "",
"to": "",
"reg": false,
"x": 2176,
"y": 1736,
"wires": [
[
"f2af85e0334b1b64"
]
]
}
]
It’s an example of getting a tree listing from a GitHub repo. Might be useful for other things.
Corresponding screenshot:
Some Notes from the Far Side
Using this setup is great but probably against some T&Cs so it’s probably not a long term good idea.
Also the upload and commit are fairly immediate, what isn’t immediate is the deployment by GitHub of the pages. This means that images are not immediately available. It’s a matter of a few minutes however not to be forgotten when the list of images gets updated and there is a broken link.
Why haven’t I created a Node-RED node package? Haven’t found the time for it and probably won’t either.
Comments powered by giscus
The author is available for Node-RED development and consultancy.